
Durchführung
| Art | ID | *.fa Datei | Länge der Sequenz | |
|---|---|---|---|---|
| Gruppe 1 | Avian myelocytomatosis virus | AF033809 | AF033809.fa | 3392 bp |
| Fujinami sarcomama virus | AF033810 | AF033810.fa | 4788 bp | |
| Avian sarcoma virus Y73 | J02027 | J02027.fa | 3718 bp | |
| Fujinami sarcoma virus | J02194 | J02194.fa | 4788 bp | |
| Avian sarcoma virus UR2 | M10455 | M10455.fa | 3166 bp | |
| Recombinant avian retrovirus MH2E21 | M14008 | M14008.fa | 2630 bp | |
| Avian myeloblastosis virus | M55076 | M55076.fa | 1929 bp | |
| Avian carcinoma virus | NC_001402 | NC_001402.fa | 2630 bp | |
| Fujinami sarcoma virus | NC_001403 | NC_001403.fa | 4788 bp | |
| Y73 sarcoma virus | NC_001404 | NC_001404.fa | 3718 bp | |
| Avian myelocytomatosis virus | NC_001866 | NC_001866.fa | 3392 bp | |
| Avian sarcoma virus CT10 | Y00302 | Y00302.fa | 2428 bp | |
| Gruppe 2 | Avian leukosis virus | AB112960 | AB112960.fa | 7448 bp |
| Rous sarcoma virus | AF033808 | AF033808.fa | 9392 bp | |
| Rous sarcoma virus strain Schmidt-Ruppin B | AF052428 | AF052428.fa | 9396 bp | |
| Avian leukosis virus strain ev-1 | AY013303 | AY013303.fa | 7525 bp | |
| Avian leukosis virus strain ev-3 | AY013304 | AY013304.fa | 5842 bp | |
| Avian leukosis virus ADOL-7501 | AY027920 | AY027920.fa | 7612 bp | |
| Rous sarcoma virus | D10652 | D10652.fa | 9317 bp | |
| Rous sarcoma virus | J02342 | J02342.fa | 9625 bp | |
| Avian leukemia virus ALV-RSA genome | M37980 | M37980.fa | 7286 bp | |
| Rous sarcoma virus | NC_001407 | NC_001407.fa | 9392 bp | |
| Avian leukosis virus | NC_001408 | NC_001408.fa | 7268 bp | |
| Avian leukosis virus HPRS-103 (subgroup J) | Z46390 | Z46390.fa | 7841 bp |
Zur weiteren Bearbeitung wurden die Sequenzen im Fasta-Format (*.fa) gespeichert.
Die Spalte ID enthält die Bezeichnungen unter denen die Sequenzen in der NCBI - Datenbank zu finden sind.
Ausserdem sind die Ausgaben der Datenbank verlinkt.
ClustalW ermöglicht die Bestimmung paarweiser und multipler Alignments (und der dazugehörigen Scorewerte).
Eingelesen wird eine *.fa Datei, in der alle Sequenzen die aligned werden sollen enthalten sind
- dazu wurden die einzelnen *.fa Dateien mit cat *.fa > x.fa in eine Ausgabedatei umgeleitet.
Ergebnis von ClustalW ist eine *.aln Datei, die das multiple Sequenzalignment der Gruppe von Sequenzen enthält.
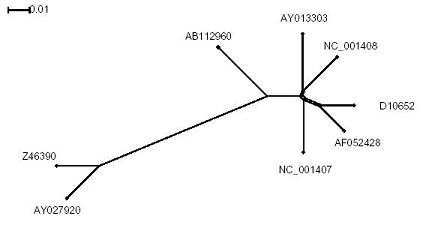
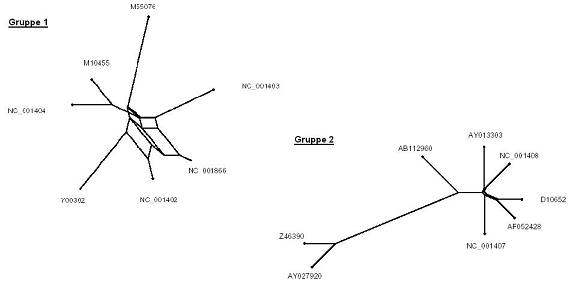
Mit den multiplen Alignments, die mit Hilfe von ClustalW erzeugt wurden, kann nun mit Splitstree der phylogenetische Baum erstellt werden.
In diesem können Ähnlichkeiten zwischen den Sequenzen aufgrund der Abstände erkannt werden.
Um die *.aln Dateien mit xsplits öffnen zu können,
mussten sie zuerst in das von Splitstree verwendete nex Format umgewandelt werden
( mit Hilfe des Perlscripts aln2nex.pl )
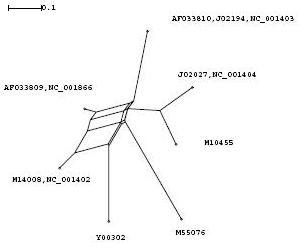
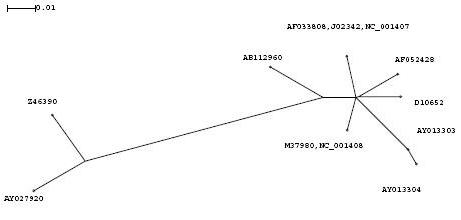
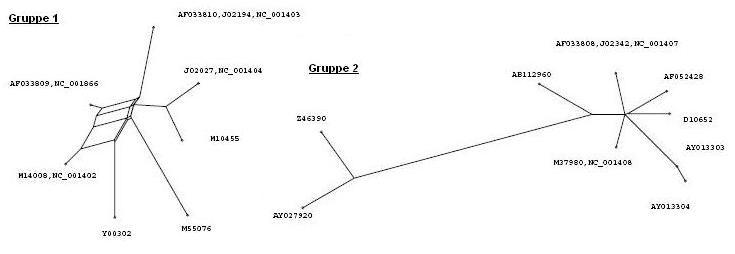
Aufgrund der phylogenetischen Bäume haben wir ein paar Sequenzen aus den beiden Gruppen entfernt, da diese äqivalent oder zumindestens sehr ähnlich zu anderen Sequenzen waren (erkennbar an der Lage im Baum)
| Art | ID | Grund für die Entfernung | |
|---|---|---|---|
| Gruppe 1 | Avian myelocytomatosis virus | AF033809 | gleiche Länge und Lage im Baum* wie NC_001866 |
| Fujinami sarcomama virus | AF033810 | gleiche Länge und Lage im Baum wie J02194 und NC_001403 | |
| Avian sarcoma virus Y73 | J02027 | gleiche Länge und Lage im Baum wie NC_001404 | |
| Fujinami sarcoma virus | J02194 | gleiche Länge und Lage im Baum wie AF033810 und NC_001403 | |
| Recombinant avian retrovirus MH2E21 | M14008 | gleiche Länge und Lage im Baum wie NC_001402 | |
| Gruppe 2 | Rous sarcoma virus | AF033808 | gleiche Länge und Lage im Baum wie NC_001407 |
| Avian leukosis virus strain ev-3 | AY013304 | ähnliche Lage im Baum wie AY013303 | |
| Rous sarcoma virus | J02342 | gleiche Lage im Baum wie NC_001407 | |
| Avian leukemia virus ALV-RSA genome | M37980 | gleiche Lage im Baum wie NC_001408 |
Nach dem ersten ClustaW - Durchlauf und Betrachtung der Ergebnisse mit Splitstree sahen die beiden Gruppen (mit denen wir dann weitergearbeitet haben) dann folgendermaßen aus:
| Art | ID | Länge der Sequenz | |
|---|---|---|---|
| Gruppe 1 | Avian sarcoma virus UR2 | M10455 | 3166 bp |
| Avian myeloblastosis virus | M55076 | 1929 bp | |
| Avian carcinoma virus | NC_001402 | 2630 bp | |
| Fujinami sarcoma virus | NC_001403 | 4788 bp | |
| Y73 sarcoma virus | NC_001404 | 3718 bp | |
| Avian myelocytomatosis virus | NC_001866 | 3392 bp | |
| Avian sarcoma virus CT10 | Y00302 | 2428 bp | |
| Gruppe 2 | Avian leukosis virus | AB112960 | 7448 bp |
| Rous sarcoma virus strain Schmidt-Ruppin B | AF052428 | 9396 bp | |
| Avian leukosis virus strain ev-1 | AY013303 | 7525 bp | |
| Avian leukosis virus ADOL-7501 | AY027920 | 7612 bp | |
| Rous sarcoma virus | D10652 | 9317 bp | |
| Rous sarcoma virus | NC_001407 | 9392 bp | |
| Avian leukosis virus | NC_001408 | 7268 bp | |
| Avian leukosis virus HPRS-103 (subgroup J) | Z46390 | 7841 bp |
Für diese Gruppen haben wir mittels ClustalW erneut die paarweisen, mulitplen Alignments bestimmen lassen:
Mit Splitstree haben wir uns dann wieder für jede Gruppe den erstellten phylogenetischen Baum angesehen:
Vienna RNA Package enthaltenen Programm RNAfold können "Minimum Free Energy Structures" (*.mfe Datei)
sowie mit der Option -p zusätzlich die Basenpaarungswahrscheinlichkeiten (*_dp.ps Datei) berechnet werden. RNAfold muss die Datei, die "gefaltet" werden soll, zuerst in das "Vienna" Format umgewandelt werden. readseq benutzt. ./readseq -a -f=19 pfad/*.fa > *.tofold *.tofold Dateien dienen als Eingabe für das RNAfold . *.mfe Dateien enthalten die Strukturvorhersage für die Sequenzen in Klammernotation. *_dp.pdf Dateien ) kennzeichnet jeder Punkt ein Basenpaar, je größer der Punkt, um so größer ist die Wahrscheinlichkeit für das Auftreten dieses Basenpaars. Alidot können konservierte Sekundärstrukturen erkannt werden. ClustalW bestimmte multiple Alignment (also die *.aln Datei)
sowie die Sekundärstrukturvorhersage die durch RNAfold erzeugt wurde (also die *.mfe - oder *_dp.ps - Dateien) benutzt. Alidot ist eine *.out Datei, die eine Tabelle enhält,
in der die verschiedenen Basenpaarungsmöglichkeiten an bestimmten Stellen in der Sequenz sowie die Wahrscheinlichkeit des Auftretens aufgelistet sind
Bedeutung der Farben in Dotplot und Mountplot:
Beide Plots bieten eine Möglichkeit zur Visualisierung der RNA-Sekundärstruktur.
| Farbe | Bedeutung |
|---|---|
| rot | in allen verglichenen Sequenzen sind die Basenpaare gleich |
| ocker | zwei verschiedene Basenpaare |
| grün | drei verschieden Basenpaare |
| türkis | vier verschieden Basenpaare |
| blau | fünf verschiedene Basenpaare |
| violett | sechs verschiedene Basenpaare |
6. weitere Bearbeitung der Daten
- ClustalX
Mit ClustalX können multiple Alignments erstellt werden.
Dazu werden die Sequenzen im FASTA Format importiert und dann im Menue der Punkt "do complete Alignment" gewählt.
Wurde vorher bereits ein multiples Alignment mit ClustalW erstellt, so ist es auch möglich die entsprechende *.aln Datei zu importieren.
Die Sequenzen werden dabei so arrangiert, daß homologe Sequenzen übereinanderliegen.
Die Farbgebung kennzeichnet die Basen:
- code2aln
Code2aln bildet ebenfalls multiple Alignments, und ist dabei in der Lage codierende bzw. nicht-codierende Regionen in den Sequenzen zu finden und überlappene codierende Regionen zu berücksichtigen
dpzoom.pl dpzoom kann man durch Angabe des ersten und letzten Nukleotids einer Teilsequenz diese vergrößert als Dotplot darstellen. dpzoom.pl -f Zahl1 -l Zahl2 aln_dp.ps > Zahl1_Zahl2_dp.ps consensus.pl consensus kann man einen Sequenzabschnitt aus dem von ClustalW erzeugten Alignment extrahieren. *.out Datei *.cons Datei stellt die Sequenz in Stringform dar, "(" die erste Base eines Basenpaares, ")" die zweite Base eines Basenpaares und "." eine ungepaarte Base darstellt.
consens.pl -f Zahl1 -l Zahl2 *.aln *.out > Zahl1_Zahl2.cons RNAplot RNAplot kann die Sequenz grafisch dargestellt werden consensus.pl *_ss.ps RNAplot < Zahl1_Zahl2.cons | Sequenz | Plot | |
|---|---|---|
| Gruppe 1 | M10455 | M10455_ss.pdf |
| M55076 | M55076_ss.pdf | |
| NC_001402 | NC_001402_ss.pdf | |
| NC_001403 | NC_001403_ss.pdf | |
| NC_001404 | NC_001404_ss.pdf | |
| NC_001866 | NC_001866_ss.pdf | |
| Y00302 | Y00302_ss.pdf | |
| Gruppe 2 | AB112960 | AB112960_ss.pdf |
| AF052428 | AF052428_ss.pdf | |
| AY013303 | AY013303_ss.pdf | |
| AY027920 | AY027920_ss.pdf | |
| D10652 | D10652_ss.pdf | |
| NC_001407 | NC_001407_ss.pdf | |
| NC_001408 | NC_001408_ss.pdf | |
| Z46390 | Z46390_ss.pdf |
anote.pl Alidot und RNAplot ,
wobei eine neue *_ss.ps Datei erzeugt wird, die die Ausgabe-Datei von RNAplot überschreibt. anote.pl *.out Zahl1_Zahl2_ss.ps cmount.pl cmount kann ein Mountplot zu einen bestimmten Bereich (oder dem gesamten Alignment) erstellt werden. dpzoom erstellte Dotplot. cmount.pl < Zahl1_Zahl2_dp.ps > Zahl1_Zahl2.mount.ps